プロンプトをタイプするのはもうやめましょう。
音声で入力するのです。
音声ディクテーションはエージェントのコンポーザーに直接組み込まれています。マイクをクリックし、プロンプトを話すと、文字起こしされたテキストがカーソル位置の下書きに挿入されます。AIコーディングエージェントのための speech-to-text であり、別途のディクテーションアプリを管理する必要も、ウィンドウ間でコピー&ペーストする必要もありません。
長く正確なプロンプトをタイプすると数分かかります。同じプロンプトを音声入力すれば数秒です。エージェントにはより多くのコンテキストを、確認のやり取りはより少なく、無駄なトークンも減らせます。価値はコードからプロンプトへ移りました。そして良いプロンプトを書く最速の方法が音声ディクテーションです。
音声ディクテーションの実演 : マイクをクリックし、プロンプトを話し、ライブの波形を見ると、speech-to-text の文字起こしがコンポーザーに届き、編集して送信できる状態になります。
音声ディクテーションが応える変化はこうです。AIコーディングエージェントと働くうえで難しいのは、もはやコードを書くことではありません。それはエージェントがやります。難しいのはプロンプトを書くことです : 何が欲しいか、制約、エッジケース、触るべきファイル、避けたい挙動を記述すること。正確なプロンプトこそが、一発成功と、十回の苛立たしいやり取りとの差を生みます。そして正確なプロンプトは長く、だからこそタイプするのが遅いのです。
音声ディクテーションはタイピングという税金を取り除きます。コンポーザーのマイクボタンをクリックし、タイプしたであろう内容を、しばしばわざわざタイプしたであろう以上のことまで話すと、speech-to-text の文字起こしが下書きに現れます。話すのは毎分150語、でもタイプは毎分150語にはなりません。音声入力は単純に速く、速いチャネルはタスクごとにより多くのコンテキストをエージェントへ渡せることを意味します。
これは後付けの機能ではありません。マイクは AgentsRoom のコンポーザーの一部で、プロンプトライブラリやスケッチツールの隣にあります。文字起こしはカーソル位置に挿入されるので、同じ下書きの中でタイプと音声入力を混ぜられます。何も自動で送られません : テキストは下書きに届き、あなたが読み、モデルが聞き間違えた一語を直し、準備ができたら Enter を押します。ここでの音声ディクテーションは書くための補助であり、自動操縦ではありません。
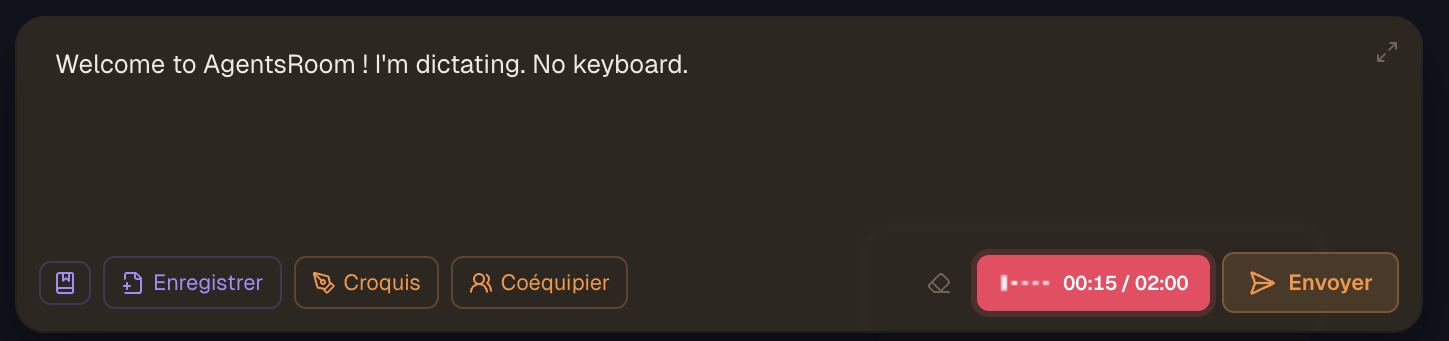
マイクボタンはコンポーザーのツールバーにあります。録音中はライブの音声波形が入力レベルを示し、その後、文字起こしされたプロンプトが下書きに現れます。
プロンプトをタイプするのではなく音声入力する理由
速さ。話す速度はタイプする速度の何倍も速く、キーを探して思考の流れを失うこともありません。タイプに3分かかる2段落のプロンプトも、音声ディクテーションなら30秒です。エージェントにプロンプトを送り続ける一日を通して、その節約は実際の数時間として返ってきます。
正確さ。音声入力はコストが低いので、あなたはより多くを話します。省いていたであろうエッジケース、名指ししなかったであろうファイル、避けてほしい挙動まで記述します。より豊かなプロンプトはより正確なプロンプトであり、より正確なプロンプトこそが、AIコーディングエージェントに一度でタスクを成功させる決め手になります。
トークンの経済性。エージェントとの確認のやり取りは毎回トークンを消費します : エージェントが尋ね、あなたが答え、コンテキストを読み直す。最初から正確に音声入力したプロンプトは、そのやり取りを丸ごと潰します。往復が減れば、同じ結果に到達するためのトークンが減り、AIコーディングの請求額をそのまま節約できます。
ハンズフリーとモバイル。デスクトップでは、エージェントが動いている間も手を空けたまま、次のプロンプトを声に出して音声入力できます。スマートフォンでは、モバイルキーボードと格闘せずにエージェントへ入力する、断然最速の方法が音声ディクテーションです。アイデアを話せば、それが Mac 上のエージェントに届きます。
音声ディクテーションの仕組み
マイクをクリック、話す、確認、送信。4ステップ、別アプリ不要、コピー&ペースト不要。
コンポーザーでマイクをクリック
エージェントのコンポーザーにカーソルを置き、ツールバーのマイクボタンをクリックします。初回は macOS がマイクの許可を求めますが、AgentsRoom がそのリクエストをシステムへ橋渡しするので、一度許可するだけで済みます。
プロンプトを話す
ボタンが録音状態に切り替わります : 入力レベルをリアルタイムで示すライブの音声波形とともに脈打つ状態になり、マイクが実際に音声を拾っていることが分かります。エージェントに知ってほしいことすべてを、あなた自身の言語で話してください。
止めると文字起こしされる
もう一度クリックして停止します。音声は選んだ文字起こしモデル(デフォルトは GPT-4o Transcribe、GPT-4o mini Transcribe、または OpenAI Whisper)へ送られます。speech-to-text の処理中、ボタンは文字起こし状態を表示します。
文字起こしがカーソル位置に届く
文字起こしされたテキストは、必要に応じて区切りの空白を入れつつ、カーソル位置の下書きに挿入されます。カーソル位置は復元されるので、そのままタイプを続けても、別の塊を音声入力しても構いません。タイプと音声入力は同じプロンプトの中で自由に混ざります。
確認して編集
まだ何も送られていません。プロンプトは下書きに残ります。読み返し、モデルが稀に聞き間違えた語を直し、キーボードで一行足し、文を並べ替える。エージェントが実際に受け取るものを、あなたが完全に制御します。
準備ができたら送信
Enter を押してプロンプトをエージェントへ送ります。タイプしたメッセージとまったく同じです。エージェントから見ればただのテキストなので、音声ディクテーションは Claude Code、Codex、Antigravity CLI、OpenCode、Aider のいずれでも同じように動きます。
プロンプトはより速く、トークンはより少なく
薄いプロンプトをタイプして反復するより、最初から良いプロンプトを音声入力するほうが安く済む理由。
薄いプロンプトは、時計に表れない形で高くつきます。エージェントは手がかりが足りず推測し、あなたが直し、コンテキスト全体を読み直し、また直す。その各ターンが入力トークン、出力トークン、キャッシュの読み込みです。機能を明確にするための3回の往復が、機能そのものより高くつくこともあります。
音声ディクテーションは経済性をひっくり返します。話すのは速いので、コンテキストを前倒しで詰め込めます : 制約、ファイルパス、避けたい挙動、頭の中にある例。エージェントは一発目に近いところで正解にたどり着きます。30秒の音声入力を、回避できた2、3回の確認サイクルと引き換えにするのです。
これは積み重なります。普通の一日は数十のプロンプトです。そのかなりの割合で音声ディクテーションが往復を1回ずつ省けば、節約されたトークンは一日、チーム、一か月を通じて積み上がります。最も安いトークンとは、自分を説明し直すために使わずに済んだトークンです。
それに、単純に摩擦が減ります。摩擦が減れば、フルバージョンをタイプするのが面倒に感じて打っていたであろう怠惰な一行ではなく、より長く良いプロンプトを実際に書くようになります。音声ディクテーションは、良いプロンプトを「楽なプロンプト」に変えるのです。
文字起こしモデルと言語を選ぶ
デスクトップの音声ディクテーションでは、設定で speech-to-text モデルと話す言語を選べます。
文字起こしモデル(デスクトップ)
- GPT-4o Transcribe(デフォルト、最高の多言語品質)
- GPT-4o mini Transcribe(ほぼ同等の精度で、より安価)
- OpenAI Whisper、whisper-1(シンプルな分単位の料金、堅実な多言語のベースライン)
話す言語
- 自動検出(デフォルト、モデルが言語を判別)
- English, Français, Español, Deutsch, Italiano, Português
- Русский, 中文, 日本語, 한국어
- العربية, हिन्दी, Bahasa Indonesia, Polski, Türkçe, Tiếng Việt
自動検出がデフォルトで、ほとんどの場合をカバーします。短い録音が誤検出されるときは特定の言語を固定しますが、固定するのは実際に話している言語だけにしてください。16言語プラス自動検出。だからあなたは自分の言葉で音声入力でき、エージェントはきれいなテキストを受け取ります。
音声ディクテーションが内部で実際にやっていること
デスクトップでは、コンポーザーがブラウザの MediaRecorder API であなたの声を録音し、その音声を AgentsRoom の文字起こしバックエンドへ送ります。文字起こしは選んだモデル上でサーバーサイドに走るので、重い speech-to-text の処理はあなたのマシンに依存せず、文字起こしはプレーンテキストとしてカーソル位置に挿入されて返ってきます。マイク、録音、挿入はすべて、すでにタイプしているのと同じコンポーザーの一部です。
モバイルでは、音声ディクテーションは意図的に別の仕組みで動きます。コンパニオンアプリはオンデバイスの音声認識を使うので、音声がスマートフォンから出ることはありません。認識されたテキストはその後、AgentsRoom のエンドツーエンド暗号化された接続を通じてデスクトップへ中継され、Mac でフォーカスしているエージェントの入力欄へ届けられます。マイクボタンを押し、話し、離すと、テキストがデスクトップのエージェントに現れます。
両方の面が一つのルールを共有します : 音声ディクテーションが自動で送ることは決してありません。デスクトップでは文字起こしが確認用に下書きへ届きます。モバイルではテキストが改行なしでフォーカス中のエージェント入力欄に貼り付けられるので、Enter はあなた自身が押します。音声入力はプロンプトを書く手段であり、それを盲目的に発射する手段ではありません。
設定はプロバイダーに依存しません。文字起こしモデルのIDは speech-to-text バックエンドに対応するものであり、エージェントの CLI に対応するものではありません。エージェントが Claude Code、Codex、Antigravity CLI、OpenCode、Aider のいずれであっても、音声入力されたテキストはコンポーザーの中ではただのテキストなので、音声ディクテーションは AgentsRoom が対応するすべてのプロバイダーで同一に振る舞います。
音声ディクテーションが使える場所
デスクトップのコンポーザーとモバイルのコンパニオンに組み込まれ、16言語で利用できます。
デスクトップのコンポーザー
macOS のエージェントコンポーザーにあるマイクボタン。GPT-4o Transcribe、GPT-4o mini Transcribe、Whisper でのサーバーサイド文字起こし。録音中のライブ音声波形、カーソル位置への文字起こし挿入、タイプとの自由な混在。設定でモデルと言語を選べます。
モバイルのコンパニオン
iOS と Android のコンパニオンでは、マイクを長押しして音声入力します。音声認識はオンデバイスで走るので音声はスマートフォンに留まり、認識されたテキストはエンドツーエンド暗号化でフォーカス中のデスクトップエージェントへ中継されます。ポケットからエージェントに入力する最速の方法です。
多言語対応
16の話し言葉プラス自動検出 : 英語、フランス語、スペイン語、ドイツ語、イタリア語、ポルトガル語、ロシア語、中国語、日本語、韓国語、アラビア語、ヒンディー語、インドネシア語、ポーランド語、トルコ語、ベトナム語。母語で音声入力すれば、エージェントはきれいに文字起こしされたテキストを受け取ります。
プロンプトをタイプする vs 音声入力する
同じエージェント、同じタスク。速度が違い、コンテキストが違い、トークンの請求額が違う。
すべてのプロンプトをタイプする
- : タイプ速度は話す速度のほんの一部なので、プロンプトは短いままになる。
- : 短いプロンプトはコンテキストを省くので、エージェントは推測し、あなたが直す。
- : 各修正がさらなる往復となり、入力トークンも出力トークンも増える。
- : 別途のディクテーションアプリやシステムのディクテーションは、ウィンドウ間のコピー&ペーストを意味する。
- : スマートフォンでは、モバイルキーボードが長いプロンプトを苦痛にするので、ほとんどプロンプトを書かなくなる。
音声ディクテーションで音声入力する
- : フルのプロンプトを数秒で話せるので、自然とより多くを語る。
- : 前倒しのコンテキストが増えれば、エージェントは一発目に近いところでタスクを成功させる。
- : 確認の往復が減れば、同じ結果に費やすトークンが減る。
- : マイクはコンポーザーの中にあり、文字起こしは下書きに届く。コピー&ペーストは不要。
- : スマートフォンではマイクを長押しすれば、暗号化された relay を通じてテキストがデスクトップのエージェントに現れる。
音声ディクテーションは、あらゆるプロンプトを同時により長く、より正確に、より速く書けるようにする、最も安い方法です。
音声入力したプロンプトはこんな感じ
これをひとつもタイプする必要はありません。声に出して話せば、speech-to-text が下のプロンプトに変え、あなたは Enter を押すだけ。これだけ詳細なプロンプトをタイプで言ってみて、どれだけ時間がかかるか体感してください。
マイクに向かって話した内容
login エンドポイントに rate limiter を追加して。
IP ごとに毎分5回の試行というスライディングウィンドウを使って。
制限に達したら Retry-After ヘッダー付きの 429 を返して。
既存の成功パスはそのまま触らないで。
制限に達したケースと、1分後にリセットされるケースのユニットテストを追加して。
signup エンドポイントには触らないで。FAQ
AgentsRoom の音声ディクテーションとは何ですか ?
音声ディクテーションは、あなたの声をテキストに変えるエージェントコンポーザー内のマイクボタンです。マイクをクリックし、プロンプトを話すと、文字起こしされたテキストがカーソル位置の下書きに挿入されます。AIコーディングエージェントへのプロンプトを書くための組み込み speech-to-text であり、別途のディクテーションアプリも、ウィンドウ間のコピー&ペーストも不要です。
プロンプトをタイプする代わりに音声入力する理由は ?
速さ、正確さ、トークンの経済性です。話す速度はタイプの何倍も速いので、プロンプトは数分ではなく数秒で済みます。音声入力はコストが低いので自然とより多くを語り、それがプロンプトをより正確にします。正確なプロンプトはエージェントとの確認の往復を減らし、同じ結果に到達するためのトークンを減らします。
どの文字起こしモデルが使えますか ?
デスクトップでは設定から3つの speech-to-text モデルを選べます : GPT-4o Transcribe(デフォルト、最高の多言語品質)、GPT-4o mini Transcribe(ほぼ同等の精度でより安価)、そして OpenAI Whisper、つまり whisper-1 モデル(シンプルな分単位の料金と堅実な多言語ベースライン)。
これは単なる OpenAI Whisper ですか ?
Whisper は選べるモデルの一つで、横で別アプリとして走らせるのではなく、コンポーザーに直接組み込まれています。GPT-4o Transcribe や GPT-4o mini Transcribe を選ぶこともできます。AgentsRoom の音声ディクテーションの要点は、音声入力がエージェントのプロンプト入力欄を直接ターゲットにすることです。だから一つのウィンドウに音声入力して別のウィンドウへコピー&ペーストする必要がありません。
音声ディクテーションはどの言語に対応していますか ?
16の話し言葉プラス自動検出 : 英語、フランス語、スペイン語、ドイツ語、イタリア語、ポルトガル語、ロシア語、中国語、日本語、韓国語、アラビア語、ヒンディー語、インドネシア語、ポーランド語、トルコ語、ベトナム語。自動検出がデフォルトです。短い録音が誤検出されるときは、設定で特定の言語を固定できます。
私の音声はサーバーに送られますか ?
面によって異なります。デスクトップでは音声が AgentsRoom の文字起こしバックエンドへ送られ、選んだモデルで speech-to-text を実行してテキストを返します。モバイルでは音声認識がオンデバイスで走るので、音声がスマートフォンから出ることはなく、認識されたテキストだけがエンドツーエンド暗号化された接続を通じてデスクトップへ中継されます。
音声入力したあと、プロンプトは自動で送信されますか ?
いいえ。音声ディクテーションは常にテキストを下書きに届けるだけで、送信は決してしません。あなたは文字起こしを読み、稀に聞き間違えられた語を直し、必要ならキーボードで追加や並べ替えをし、準備ができたら Enter を押します。エージェントが受け取るものを正確にあなたが制御します。
同じプロンプトの中でタイプと音声入力を混ぜられますか ?
はい。文字起こしは下書き全体の代わりではなく、カーソル位置に挿入されます。だから前半をタイプし、途中で長い段落を音声入力し、最後の一行をタイプできます。音声ディクテーションはコンポーザーを埋めるより速い方法であり、キーボードと完全に両立します。
スマートフォンから Mac 上のエージェントへ音声入力できますか ?
はい。モバイルのコンパニオンアプリにはマイクボタンがあります : 長押しし、話し、離します。音声はオンデバイスで認識され、テキストはエンドツーエンド暗号化でデスクトップでフォーカスしているエージェントへ中継されます。モバイルキーボードを使わずに Mac のエージェントへプロンプトを送る最速の方法です。
音声ディクテーションは Claude Code、Codex、Antigravity で動きますか ?
はい、すべてで動きます。さらに OpenCode と Aider でも。音声入力されたテキストはコンポーザーの中ではただのテキストで、文字起こしの設定はプロバイダーに依存しないので、どのエージェント CLI を走らせていても音声ディクテーションは同一に振る舞います。
相性のよい機能
スクラッチパッド
フッターにある、より大きなプロンプトエディター。長いブリーフを音声入力し、スクラッチパッドで練り上げ、エージェントへ送ります。
プロンプトライブラリ
音声入力したプロンプトを再利用できるテンプレートとして保存。音声が初稿を書き、ライブラリが良いものを残します。
モバイル・デスクトップ同期
音声入力したテキストをスマートフォンから Mac のフォーカス中のエージェントへ運ぶ、エンドツーエンド暗号化されたリンク。
エージェントのリモート操作
デスクトップのエージェントをスマートフォンから操作。音声入力は、キーボードを離れているときにプロンプトを送る最速の方法です。
マルチプロバイダー
Claude、Codex、Antigravity、OpenCode、Aider を並べて走らせる。音声ディクテーションはそのすべてで同じように動きます。
スケッチ
コンポーザーで描いて注釈をつける。音声入力したプロンプトに手早いスケッチを添えれば、エージェントに言葉と絵の両方を渡せます。
エージェントに話しかけ、プロンプトをタイプするのをやめる
AgentsRoom をダウンロードして、プロンプトをコンポーザーへそのまま音声入力しましょう。書くのはより速く、コンテキストはより豊かに、トークンはより軽く。AIコーディングIDEに組み込まれた音声ディクテーションを、デスクトップでもモバイルでも。
コンパニオンアプリ:外出先でもエージェントを確認
Claude、Codex、Antigravity CLI、またはその他の AI プロバイダーを使用します。
バグや要望を公開バックログに直接送信できます。
実際の AgentsRoom の様子。