Przestań wpisywać prompty.
Dyktuj je.
Dyktowanie głosowe działa wprost w composerze agenta. Kliknij mikrofon, wypowiedz swój prompt, a przepisany tekst trafia do wersji roboczej w miejscu kursora. Zamiana mowy na tekst dla twoich agentów do kodowania, bez osobnej aplikacji do dyktowania, którą trzeba pilnować, i bez kopiowania między oknami.
Wpisanie długiego, precyzyjnego promptu zajmuje minuty. Podyktowanie tego samego promptu zajmuje sekundy. Więcej kontekstu dla agenta, mniej rund doprecyzowywania, mniej zmarnowanych tokenów. Wartość przeniosła się z kodu na prompt, a dyktowanie głosowe to najszybszy sposób, by napisać dobry.
Dyktowanie głosowe w akcji : kliknij mikrofon, wypowiedz prompt, obserwuj falę dźwięku na żywo, a transkrypcja mowy na tekst ląduje w composerze gotowa do edycji i wysłania.
Oto zmiana, na którą odpowiada dyktowanie głosowe. Najtrudniejsza część pracy z agentem AI do kodowania to już nie pisanie kodu, bo robi to agent. Najtrudniejsze jest napisanie promptu : opisanie tego, czego chcesz, ograniczeń, przypadków brzegowych, pliku do zmiany, zachowania, którego należy unikać. Precyzyjny prompt to różnica między jednym strzałem a dziesięcioma frustrującymi rundami. A precyzyjny prompt jest długi, więc wolno się go wpisuje.
Dyktowanie głosowe znosi podatek od pisania. Klikasz przycisk mikrofonu w composerze, mówisz wszystko, co byś wpisał, często więcej, niż chciałoby ci się wpisać, a transkrypcja mowy na tekst pojawia się w wersji roboczej. Mówisz w tempie 150 słów na minutę, ale nie piszesz w tempie 150 słów na minutę. Dyktowanie jest po prostu szybsze, a szybszy kanał oznacza, że dajesz agentowi więcej kontekstu na zadanie.
To nie jest doczepiony dodatek. Mikrofon jest częścią composera AgentsRoom, obok biblioteki promptów i narzędzi do szkicowania. Transkrypcja wstawia się w miejscu kursora, więc możesz łączyć pisanie i dyktowanie w tej samej wersji roboczej. Nic nie wysyła się automatycznie : tekst ląduje w wersji roboczej, czytasz go, poprawiasz to jedno słowo, które model źle usłyszał, i naciskasz Enter, gdy jesteś gotowy. Dyktowanie głosowe jest tu pomocą w pisaniu, a nie autopilotem.
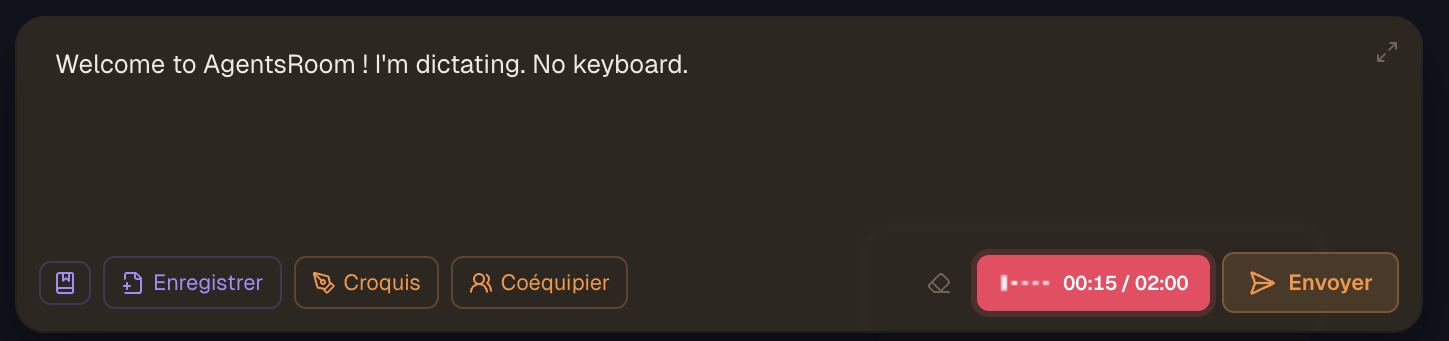
Przycisk mikrofonu znajduje się na pasku narzędzi composera. Podczas nagrywania fala głosu na żywo pokazuje poziom sygnału, a następnie przepisany prompt pojawia się w wersji roboczej.
Dlaczego dyktować prompty zamiast je wpisywać
Szybkość. Mówisz wielokrotnie szybciej, niż piszesz, i nie tracisz wątku w pogoni za klawiszami. Prompt na dwa akapity, który zajmuje trzy minuty wpisywania, to trzydzieści sekund dyktowania głosowego. W ciągu całego dnia promptowania agentów ten zaoszczędzony czas sumuje się w realne godziny.
Precyzja. Ponieważ dyktowanie jest tanie, mówisz więcej. Opisujesz przypadek brzegowy, który byś pominął, plik, którego byś nie nazwał, zachowanie, którego chcesz uniknąć. Bogatszy prompt to bardziej precyzyjny prompt, a bardziej precyzyjny prompt to dokładnie to, dzięki czemu agent AI do kodowania trafia w zadanie za pierwszym razem.
Oszczędność tokenów. Każda runda doprecyzowywania z agentem kosztuje tokeny : agent pyta, ty odpowiadasz, on ponownie czyta kontekst. Precyzyjny podyktowany prompt z góry zwija te rundy. Mniej tam i z powrotem to mniej tokenów wydanych na ten sam wynik, czyli bezpośrednia oszczędność na rachunku za kodowanie z AI.
Wolne ręce i mobilność. Na desktopie masz wolne ręce, gdy agent pracuje, i dyktujesz na głos kolejny prompt. W telefonie dyktowanie głosowe to zdecydowanie najszybszy sposób, by nakarmić agenta bez walki z klawiaturą mobilną. Wypowiedz pomysł, a wyląduje on w twoim agencie na Macu.
Jak działa dyktowanie głosowe
Kliknij mikrofon, mów, przejrzyj, wyślij. Cztery kroki, bez osobnej aplikacji, bez kopiowania.
Kliknij mikrofon w composerze
Ustaw kursor w composerze agenta i kliknij przycisk mikrofonu na pasku narzędzi. Za pierwszym razem macOS poprosi o pozwolenie na mikrofon, a AgentsRoom przekazuje to żądanie do systemu, więc udzielasz go raz.
Wypowiedz swój prompt
Przycisk przełącza się w tryb nagrywania : pulsujący stan z falą głosu na żywo, która w czasie rzeczywistym pokazuje poziom sygnału, więc wiesz, że mikrofon faktycznie rejestruje dźwięk. Powiedz wszystko, co twój agent ma wiedzieć, we własnym języku.
Zatrzymaj, a system przepisze
Kliknij ponownie, by zatrzymać. Dźwięk trafia do wybranego modelu transkrypcji (GPT-4o Transcribe domyślnie, GPT-4o mini Transcribe lub OpenAI Whisper). Przycisk pokazuje stan transkrypcji, gdy działa zamiana mowy na tekst.
Transkrypcja ląduje w miejscu kursora
Przepisany tekst wstawia się do wersji roboczej w miejscu kursora, w razie potrzeby z oddzielającą spacją. Pozycja kursora zostaje przywrócona, więc możesz dalej pisać albo podyktować kolejny fragment. Pisanie i dyktowanie swobodnie się mieszają w tym samym prompcie.
Przejrzyj i popraw
Nic jeszcze nie zostało wysłane. Prompt czeka w wersji roboczej. Przeczytaj go, popraw rzadkie słowo, które model źle usłyszał, dodaj linijkę z klawiatury, przestaw zdanie. Zachowujesz pełną kontrolę nad tym, co naprawdę otrzymuje twój agent.
Wyślij, gdy będziesz gotowy
Naciśnij Enter, by wysłać prompt do agenta, dokładnie jak wpisaną wiadomość. Z punktu widzenia agenta to tylko tekst, więc dyktowanie głosowe działa tak samo z Claude Code, Codex, Antigravity CLI, OpenCode i Aider.
Szybsze prompty, mniej tokenów
Dlaczego podyktowanie lepszego promptu z góry jest tańsze niż wpisanie chudego i iterowanie.
Chudy prompt jest drogi w sposób, który nie widać na zegarze. Agent nie ma na czym oprzeć działania, więc zgaduje, ty poprawiasz, on ponownie czyta cały kontekst, ty znów poprawiasz. Każda z tych tur to tokeny wejściowe, tokeny wyjściowe i odczyty z pamięci podręcznej. Trzy rundy doprecyzowywania funkcji potrafią kosztować więcej niż sama funkcja.
Dyktowanie głosowe odwraca tę ekonomię. Ponieważ mówienie jest szybkie, ładujesz kontekst z góry : ograniczenia, ścieżki plików, zachowanie do uniknięcia, przykład, który masz w głowie. Agent trafia bliżej za pierwszym razem. Wymieniasz trzydzieści sekund dyktowania na dwa czy trzy uniknięte cykle doprecyzowywania.
To się kumuluje. Normalny dzień to dziesiątki promptów. Jeśli dyktowanie głosowe oszczędza jedną rundę przy dużej części z nich, zaoszczędzone tokeny piętrzą się przez cały dzień, w całym zespole, przez cały miesiąc. Najtańszy token to ten, którego nigdy nie musiałeś wydać na ponowne tłumaczenie się.
To też po prostu mniej tarcia. Mniej tarcia oznacza, że faktycznie piszesz dłuższy, lepszy prompt zamiast leniwej jednolinijkówki, którą byś wpisał, bo wpisywanie pełnej wersji wydawało się zbyt dużą robotą. Dyktowanie głosowe sprawia, że dobry prompt staje się łatwym promptem.
Wybierz model transkrypcji i język
Dyktowanie głosowe na desktopie pozwala wybrać w ustawieniach model zamiany mowy na tekst oraz język, którym mówisz.
Modele transkrypcji (desktop)
- GPT-4o Transcribe (domyślny, najlepsza jakość wielojęzyczna)
- GPT-4o mini Transcribe (niemal tak dokładny, tańszy)
- OpenAI Whisper, whisper-1 (prosty cennik za minutę, solidna baza wielojęzyczna)
Języki mówione
- Automatyczne wykrywanie (domyślne, model sam ustala język)
- English, Français, Español, Deutsch, Italiano, Português
- Русский, 中文, 日本語, 한국어
- العربية, हिन्दी, Bahasa Indonesia, Polski, Türkçe, Tiếng Việt
Automatyczne wykrywanie jest domyślne i radzi sobie z większością przypadków. Wymuś konkretny język, gdy krótkie nagrania są źle rozpoznawane, ale wymuszaj tylko ten język, którym faktycznie mówisz. Szesnaście języków plus automatyczne wykrywanie, więc dyktujesz własnymi słowami, a agent dostaje czysty tekst.
Co dyktowanie głosowe naprawdę robi pod maską
Na desktopie composer nagrywa twój głos przez przeglądarkowe API MediaRecorder i wysyła dźwięk do backendu transkrypcji AgentsRoom. Transkrypcja działa po stronie serwera na wybranym modelu, więc ciężka praca rozpoznawania mowy nie zależy od twojej maszyny, a transkrypcja wraca jako zwykły tekst wstawiony w miejscu kursora. Mikrofon, nagrywanie i wstawianie to wszystko części tego samego composera, w którym już piszesz.
W aplikacji mobilnej dyktowanie głosowe działa inaczej, i to celowo. Aplikacja towarzysząca korzysta z rozpoznawania mowy na urządzeniu, więc dźwięk nigdy nie opuszcza telefonu. Rozpoznany tekst jest następnie przekazywany do desktopa przez połączenie AgentsRoom szyfrowane od końca do końca i wstawiany do pola agenta, który masz aktywny na Macu. Przytrzymaj przycisk mikrofonu, mów, puść, a tekst pojawia się w agencie na desktopie.
Obie powierzchnie dzielą jedną zasadę : dyktowanie głosowe nigdy nie wysyła samo z siebie. Na desktopie transkrypcja ląduje w wersji roboczej do przejrzenia. W aplikacji mobilnej tekst jest wklejany do pola aktywnego agenta bez znaku końca wiersza, więc Enter naciskasz sam. Dyktowanie to sposób na napisanie promptu, a nie na wystrzelenie go w ciemno.
Konfiguracja jest neutralna wobec dostawcy. Identyfikatory modeli transkrypcji odnoszą się do backendu zamiany mowy na tekst, a nie do CLI twojego agenta. Niezależnie od tego, czy twoim agentem jest Claude Code, Codex, Antigravity CLI, OpenCode czy Aider, podyktowany tekst to tylko tekst w composerze, więc dyktowanie głosowe zachowuje się identycznie u każdego dostawcy obsługiwanego przez AgentsRoom.
Gdzie działa dyktowanie głosowe
Wbudowane w composer desktopowy i aplikację towarzyszącą mobilną, w szesnastu językach.
Composer desktopowy
Przycisk mikrofonu w composerze agenta na macOS. Transkrypcja po stronie serwera na GPT-4o Transcribe, GPT-4o mini Transcribe lub Whisper. Fala głosu na żywo podczas nagrywania, transkrypcja wstawiana w miejscu kursora, dowolne łączenie z pisaniem. Wybierz model i język w ustawieniach.
Aplikacja towarzysząca mobilna
W aplikacji towarzyszącej na iOS i Androida przytrzymaj mikrofon, by dyktować. Rozpoznawanie mowy działa na urządzeniu, więc dźwięk zostaje w telefonie, a rozpoznany tekst jest przekazywany szyfrowaniem od końca do końca do aktywnego agenta na desktopie. Najszybszy sposób, by nakarmić agenta prosto z kieszeni.
Wielojęzyczne
Szesnaście języków mówionych plus automatyczne wykrywanie : angielski, francuski, hiszpański, niemiecki, włoski, portugalski, rosyjski, chiński, japoński, koreański, arabski, hindi, indonezyjski, polski, turecki i wietnamski. Dyktuj w ojczystym języku, a agent otrzymuje czysty przepisany tekst.
Wpisywanie promptów kontra ich dyktowanie
Ten sam agent, to samo zadanie. Inna szybkość, inny kontekst, inny rachunek za tokeny.
Wpisywanie każdego promptu
- : Piszesz z ułamkiem prędkości, z jaką mówisz, więc prompty pozostają krótkie.
- : Krótkie prompty pomijają kontekst, więc agent zgaduje, a ty go poprawiasz.
- : Każda poprawka to kolejna runda, więcej tokenów wejściowych i wyjściowych.
- : Osobna aplikacja do dyktowania albo dyktowanie systemowe oznacza kopiowanie między oknami.
- : W telefonie klawiatura mobilna sprawia, że długie prompty są męczarnią, więc prawie wcale nie promptujesz.
Dyktowanie z dyktowaniem głosowym
- : Wypowiadasz cały prompt w kilka sekund, więc naturalnie mówisz więcej.
- : Więcej kontekstu z góry oznacza, że agent trafia w zadanie bliżej za pierwszym razem.
- : Mniej rund doprecyzowywania oznacza mniej tokenów wydanych na ten sam wynik.
- : Mikrofon jest w composerze, transkrypcja ląduje w wersji roboczej, bez kopiowania.
- : W telefonie przytrzymaj mikrofon, a tekst pojawia się w twoim agencie na desktopie przez szyfrowany relay.
Dyktowanie głosowe to najtańszy sposób, by każdy prompt był jednocześnie dłuższy, bardziej precyzyjny i szybszy do napisania.
Jak brzmi podyktowany prompt
Nie musisz nic z tego pisać. Mówisz to na głos, zamiana mowy na tekst przekształca to w poniższy prompt, a ty naciskasz Enter. Spróbuj wpisać tak szczegółowy prompt z klawiatury i poczuj, ile to trwa.
Podyktowane do mikrofonu
Dodaj rate limiter na endpoincie logowania.
Użyj przesuwnego okna pięciu prób na minutę na jedno IP.
Zwróć 429 z nagłówkiem Retry-After, gdy limit zostanie osiągnięty.
Nie ruszaj istniejącej ścieżki sukcesu.
Dodaj test jednostkowy dla osiągnięcia limitu i jeden dla jego resetu po minucie.
Nie ruszaj endpointu rejestracji.FAQ
Czym jest dyktowanie głosowe w AgentsRoom ?
Dyktowanie głosowe to przycisk mikrofonu w composerze agenta, który zamienia twoją mowę na tekst. Klikasz mikrofon, wypowiadasz swój prompt, a przepisany tekst wstawia się do wersji roboczej w miejscu kursora. To wbudowana zamiana mowy na tekst do pisania promptów dla twoich agentów AI do kodowania, bez osobnej aplikacji do dyktowania i bez kopiowania między oknami.
Po co dyktować prompty zamiast je wpisywać ?
Szybkość, precyzja i oszczędność tokenów. Mówisz wielokrotnie szybciej, niż piszesz, więc prompty zajmują sekundy zamiast minut. Ponieważ dyktowanie jest tanie, naturalnie mówisz więcej, co czyni prompt bardziej precyzyjnym. Precyzyjny prompt to mniej rund doprecyzowywania z agentem, czyli mniej tokenów wydanych na ten sam wynik.
Których modeli transkrypcji mogę używać ?
Na desktopie wybierasz w ustawieniach spośród trzech modeli zamiany mowy na tekst : GPT-4o Transcribe (domyślny, najlepsza jakość wielojęzyczna), GPT-4o mini Transcribe (niemal tak dokładny i tańszy) oraz OpenAI Whisper, model whisper-1 z prostym cennikiem za minutę i solidną bazą wielojęzyczną.
Czy to po prostu OpenAI Whisper ?
Whisper to jeden z modeli, które możesz wybrać, wbudowany wprost w composer, a nie działający jako osobna aplikacja z boku. Możesz też wybrać GPT-4o Transcribe lub GPT-4o mini Transcribe. Sens dyktowania głosowego w AgentsRoom polega na tym, że dyktowanie trafia wprost do pola promptu twojego agenta, więc nie dyktujesz w jednym oknie, by kopiować do drugiego.
Jakie języki obsługuje dyktowanie głosowe ?
Szesnaście języków mówionych plus automatyczne wykrywanie : angielski, francuski, hiszpański, niemiecki, włoski, portugalski, rosyjski, chiński, japoński, koreański, arabski, hindi, indonezyjski, polski, turecki i wietnamski. Automatyczne wykrywanie jest domyślne. Możesz wymusić konkretny język w ustawieniach, gdy krótkie nagrania są źle rozpoznawane.
Czy mój głos jest wysyłany na serwer ?
To zależy od powierzchni. Na desktopie dźwięk jest wysyłany do backendu transkrypcji AgentsRoom, który wykonuje zamianę mowy na tekst na wybranym modelu i zwraca tekst. W aplikacji mobilnej rozpoznawanie mowy działa na urządzeniu, więc dźwięk nigdy nie opuszcza telefonu, a do desktopa przez połączenie szyfrowane od końca do końca przekazywany jest tylko rozpoznany tekst.
Czy prompt wysyła się automatycznie po podyktowaniu ?
Nie. Dyktowanie głosowe zawsze ląduje tekstem w wersji roboczej, nigdy nie wysyła. Czytasz transkrypcję, poprawiasz rzadkie źle usłyszane słowo, dodajesz lub przestawiasz z klawiatury, jeśli chcesz, i naciskasz Enter, gdy jesteś gotowy. Zachowujesz kontrolę nad tym, co dokładnie otrzymuje twój agent.
Czy mogę łączyć pisanie i dyktowanie w tym samym prompcie ?
Tak. Transkrypcja wstawia się w miejscu kursora, a nie w miejsce całej wersji roboczej. Możesz więc wpisać pierwszą połowę, podyktować długi akapit w środku, a potem dopisać ostatnią linijkę. Dyktowanie głosowe to szybszy sposób wypełniania composera, w pełni zgodny z klawiaturą.
Czy mogę dyktować z telefonu do agenta na moim Macu ?
Tak. Aplikacja towarzysząca mobilna ma przycisk mikrofonu : przytrzymaj go, mów, puść. Mowa jest rozpoznawana na urządzeniu, a tekst przekazywany szyfrowaniem od końca do końca do agenta, który masz aktywny na desktopie. To najszybszy sposób, by przesłać prompt do agenta na Macu bez klawiatury mobilnej.
Czy dyktowanie głosowe działa z Claude Code, Codex i Antigravity ?
Tak, ze wszystkimi, a do tego z OpenCode i Aider. Podyktowany tekst to tylko tekst w composerze, a konfiguracja transkrypcji jest neutralna wobec dostawcy, więc dyktowanie głosowe zachowuje się identycznie niezależnie od tego, które CLI agenta uruchamiasz.
Dobrze łączy się z
Scratchpad
Większy edytor promptów w stopce. Podyktuj długi brief, dopracuj go w scratchpadzie, a potem wyślij do agenta.
Biblioteka promptów
Zapisuj dyktowane prompty jako szablony do ponownego użycia. Głos pisze pierwszy szkic, biblioteka przechowuje te dobre.
Synchronizacja mobile-desktop
Łącze szyfrowane od końca do końca, które niesie twój podyktowany tekst z telefonu do aktywnego agenta na twoim Macu.
Zdalne sterowanie agentami
Steruj agentami na desktopie z telefonu. Dyktowanie to najszybszy sposób, by przesłać im prompt, gdy jesteś z dala od klawiatury.
Wielu dostawców
Uruchamiaj Claude, Codex, Antigravity, OpenCode i Aider obok siebie. Dyktowanie głosowe działa tak samo z każdym z nich.
Sketch
Rysuj i opisuj w composerze. Połącz podyktowany prompt z szybkim szkicem, by dać agentowi i słowa, i obraz.
Mów do agentów, przestań wpisywać prompty
Pobierz AgentsRoom i dyktuj prompty prosto do composera. Szybsze do napisania, bogatsze w kontekst, lżejsze w tokeny. Dyktowanie głosowe wbudowane w twoje IDE do kodowania z AI, na desktopie i w aplikacji mobilnej.
Aplikacja towarzyszaca: monitoruj agentów w podrozy
Użyj Claude, Codex, Antigravity CLI lub innego dostawcy AI.
Wysyłaj bugi i prośby bezpośrednio do swojego publicznego backlogu.
Spojrzenie na AgentsRoom w akcji.