Arrêtez de taper vos prompts.
Dictez-les.
La dictée vocale vit directement dans le composer de l'agent. Cliquez le micro, dictez votre prompt, et le texte transcrit s'insère dans le brouillon à l'emplacement du curseur. De la reconnaissance vocale pour vos agents de code, sans app de dictée séparée à gérer et sans copier-coller entre deux fenêtres.
Taper un prompt long et précis prend des minutes. Le dicter prend quelques secondes. Plus de contexte pour votre agent, moins d'allers-retours de clarification, moins de tokens gaspillés. La valeur est passée du code au prompt, et la dictée vocale est le moyen le plus rapide d'en écrire un bon.
La dictée vocale en action : cliquez le micro, dictez le prompt, regardez la forme d'onde en direct, et la transcription s'insère dans le composer, prête à éditer puis envoyer.
Voici le basculement auquel répond la dictée vocale. Le plus dur, avec un agent IA, ce n'est plus d'écrire le code, l'agent le fait. Le plus dur, c'est d'écrire le prompt : décrire ce que vous voulez, les contraintes, les cas limites, le fichier à toucher, le comportement à éviter. Un prompt précis fait la différence entre un coup réussi et dix allers-retours pénibles. Et un prompt précis, c'est long, donc lent à taper.
La dictée vocale supprime la taxe de la frappe. Vous cliquez le bouton micro du composer, vous dites tout ce que vous auriez tapé, souvent plus que ce que vous auriez pris la peine de taper, et la transcription apparaît dans le brouillon. Vous parlez à 150 mots par minute, vous ne tapez pas à 150 mots par minute. La dictée est juste plus rapide, et un canal plus rapide veut dire plus de contexte par tâche pour votre agent.
Ce n'est pas un greffon. Le micro fait partie du composer AgentsRoom, à côté de la bibliothèque de prompts et des outils de dessin. Le texte s'insère à votre curseur, vous mélangez donc frappe et dictée dans le même brouillon. Rien ne part tout seul : le texte atterrit dans le brouillon, vous le relisez, vous corrigez le mot que le modèle a mal entendu, et vous envoyez avec Entrée quand vous êtes prêt. Ici, la dictée vocale est une aide à l'écriture, pas un pilote automatique.
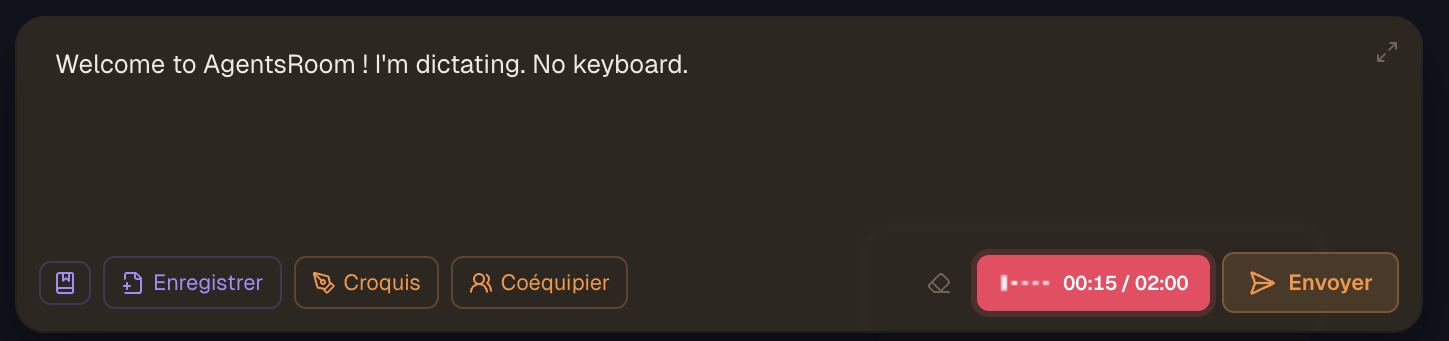
Le bouton micro se trouve dans la barre d'outils du composer. Pendant l'enregistrement, une forme d'onde en direct montre le niveau, puis le prompt transcrit apparaît dans le brouillon.
Pourquoi dicter vos prompts plutôt que les taper
La vitesse. Vous parlez bien plus vite que vous ne tapez, et vous ne perdez pas le fil à chercher vos touches. Un prompt de deux paragraphes qui prendrait trois minutes à taper, c'est trente secondes de dictée. Sur une journée entière à prompter vos agents, ce temps gagné se compte en heures.
La précision. Comme la dictée ne coûte presque rien, vous en dites plus. Vous décrivez le cas limite que vous auriez sauté, le fichier que vous n'auriez pas nommé, le comportement à éviter. Un prompt plus riche est un prompt plus précis, et c'est exactement ce qui fait qu'un agent IA réussit la tâche du premier coup.
L'économie de tokens. Chaque aller-retour de clarification avec un agent coûte des tokens : l'agent demande, vous répondez, il relit le contexte. Un prompt dicté précis dès le départ écrase ces allers-retours. Moins de va-et-vient, ce sont moins de tokens dépensés pour le même résultat, donc une économie directe sur votre facture d'IA.
Mains libres et mobile. Sur le desktop, vous gardez les mains libres pendant qu'un agent tourne et vous dictez le prompt suivant à voix haute. Sur le téléphone, la dictée vocale est de loin le moyen le plus rapide d'alimenter un agent sans se battre avec un clavier mobile. Dites l'idée, elle atterrit dans votre agent sur le Mac.
Comment marche la dictée vocale
Cliquez le micro, dictez, relisez, envoyez. Quatre gestes, sans app séparée, sans copier-coller.
Cliquez le micro dans le composer
Placez votre curseur dans le composer de l'agent et cliquez le bouton micro de la barre d'outils. La première fois, macOS demande l'autorisation du micro, AgentsRoom route la demande vers le système pour que vous l'accordiez une seule fois.
Dictez votre prompt
Le bouton passe en enregistrement : un état pulsé avec une forme d'onde en direct qui montre votre niveau d'entrée en temps réel, pour savoir que le micro capte bien. Dites tout ce que votre agent doit savoir, dans votre langue.
Arrêtez, ça transcrit
Cliquez à nouveau pour arrêter. L'audio part vers le modèle de transcription choisi (GPT-4o Transcribe par défaut, GPT-4o mini Transcribe, ou Whisper). Le bouton affiche un état de transcription pendant le travail de reconnaissance.
Le texte arrive à votre curseur
Le texte transcrit s'insère dans le brouillon à l'emplacement du curseur, avec un espace de séparation au besoin. Votre position est restaurée, vous pouvez continuer à taper ou dicter un autre morceau. Frappe et dictée se mélangent librement dans le même prompt.
Relisez et corrigez
Rien n'est encore envoyé. Le prompt reste dans le brouillon. Relisez-le, corrigez le rare mot mal entendu, ajoutez une ligne au clavier, réorganisez une phrase. Vous gardez le contrôle total de ce que votre agent reçoit vraiment.
Envoyez quand vous êtes prêt
Appuyez sur Entrée pour envoyer le prompt à votre agent, exactement comme un message tapé. Pour l'agent, ce n'est que du texte, donc la dictée vocale fonctionne pareil avec Claude Code, Codex, Antigravity CLI, OpenCode et Aider.
Des prompts plus rapides, moins de tokens
Pourquoi dicter un bon prompt dès le départ coûte moins cher que taper un prompt maigre puis itérer.
Un prompt maigre coûte cher d'une façon qui ne se voit pas sur l'horloge. L'agent n'a pas assez d'éléments, donc il devine, vous corrigez, il relit tout le contexte, vous corrigez encore. Chacun de ces tours, ce sont des tokens d'entrée, de sortie et des lectures de cache. Trois allers-retours pour clarifier une feature peuvent coûter plus cher que la feature elle-même.
La dictée vocale renverse l'équation. Comme parler est rapide, vous chargez le contexte en amont : les contraintes, les chemins de fichiers, le comportement à éviter, l'exemple que vous avez en tête. L'agent vise juste plus près du premier coup. Vous échangez trente secondes de dictée contre deux ou trois cycles de clarification évités.
Et ça se cumule. Une journée normale, ce sont des dizaines de prompts. Si la dictée vocale économise un aller-retour sur une bonne partie d'entre eux, les tokens économisés s'empilent sur la journée, sur l'équipe, sur le mois. Le token le moins cher est celui que vous n'avez jamais eu à dépenser pour vous réexpliquer.
C'est aussi simplement moins de friction. Moins de friction, c'est écrire le prompt long et détaillé au lieu du one-liner paresseux que vous auriez tapé parce que taper la version complète semblait trop de travail. La dictée vocale rend le bon prompt facile à écrire.
Choisissez votre modèle de transcription et votre langue
Sur le desktop, la dictée vocale vous laisse choisir le modèle de reconnaissance et la langue parlée dans les réglages.
Modèles de transcription (desktop)
- GPT-4o Transcribe (défaut, meilleure qualité multilingue)
- GPT-4o mini Transcribe (presque aussi précis, moins cher)
- Whisper d'OpenAI, whisper-1 (tarif simple à la minute, base multilingue solide)
Langues parlées
- Auto-détection (défaut, le modèle devine la langue)
- Français, English, Español, Deutsch, Italiano, Português
- Русский, 中文, 日本語, 한국어
- العربية, हिन्दी, Bahasa Indonesia, Polski, Türkçe, Tiếng Việt
L'auto-détection est le défaut et gère la plupart des cas. Forcez une langue précise quand les courts enregistrements sont mal détectés, mais ne forcez que la langue que vous parlez vraiment. Seize langues plus l'auto-détection, vous dictez dans vos mots et votre agent reçoit un texte propre.
Ce que la dictée vocale fait vraiment sous le capot
Sur le desktop, le composer enregistre votre voix avec l'API navigateur MediaRecorder et envoie l'audio au backend de transcription d'AgentsRoom. La transcription tourne côté serveur sur le modèle choisi, le gros du travail de reconnaissance ne dépend donc pas de votre machine, et le texte revient en clair, inséré à votre curseur. Le micro, l'enregistrement et l'insertion font tous partie du même composer dans lequel vous tapez déjà.
Sur mobile, la dictée vocale fonctionne autrement, volontairement. L'app compagnon utilise la reconnaissance vocale on-device, l'audio ne quitte donc pas votre téléphone. Le texte reconnu est ensuite relayé vers le desktop via la connexion chiffrée de bout en bout d'AgentsRoom et déposé dans l'input de l'agent que vous avez focalisé sur le Mac. Maintenez le micro, parlez, relâchez, le texte apparaît dans votre agent desktop.
Les deux surfaces partagent une règle : la dictée vocale n'envoie jamais d'elle-même. Sur desktop, la transcription atterrit dans le brouillon pour relecture. Sur mobile, le texte est collé dans l'input de l'agent focalisé sans retour chariot, vous appuyez donc vous-même sur Entrée. La dictée sert à écrire le prompt, pas à le déclencher à l'aveugle.
La configuration est neutre vis-à-vis du provider. Les identifiants de modèles mappent le backend de reconnaissance, pas le CLI de votre agent. Que votre agent soit Claude Code, Codex, Antigravity CLI, OpenCode ou Aider, le texte dicté n'est que du texte dans le composer, la dictée vocale se comporte donc à l'identique sur tous les providers supportés par AgentsRoom.
Où marche la dictée vocale
Intégrée au composer desktop et à l'app compagnon mobile, en seize langues.
Composer desktop
Un bouton micro dans le composer de l'agent sur macOS. Transcription côté serveur sur GPT-4o Transcribe, GPT-4o mini Transcribe ou Whisper. Forme d'onde en direct pendant l'enregistrement, texte inséré au curseur, mélange libre avec la frappe. Choisissez modèle et langue dans les réglages.
App compagnon mobile
Sur le compagnon iOS et Android, maintenez le micro pour dicter. La reconnaissance tourne on-device, l'audio reste donc sur le téléphone, et le texte reconnu est relayé chiffré de bout en bout vers l'agent desktop focalisé. Le moyen le plus rapide d'alimenter un agent depuis votre poche.
Multilingue
Seize langues parlées plus la détection automatique : anglais, français, espagnol, allemand, italien, portugais, russe, chinois, japonais, coréen, arabe, hindi, indonésien, polonais, turc et vietnamien. Dictez dans votre langue, votre agent reçoit un texte transcrit propre.
Taper ses prompts vs les dicter
Même agent, même tâche. Vitesse différente, contexte différent, facture de tokens différente.
Taper chaque prompt
- : Vous tapez à une fraction de votre vitesse de parole, les prompts restent donc courts.
- : Les prompts courts sautent du contexte, l'agent devine et vous le corrigez.
- : Chaque correction est un aller-retour de plus, plus de tokens d'entrée et de sortie.
- : Une app de dictée séparée ou la dictée système impose du copier-coller entre fenêtres.
- : Sur le téléphone, le clavier mobile rend les longs prompts pénibles, vous ne promptez presque plus.
Dicter avec la dictée vocale
- : Vous dictez le prompt complet en quelques secondes, vous en dites donc plus naturellement.
- : Plus de contexte en amont, l'agent vise juste plus près du premier coup.
- : Moins d'allers-retours de clarification, moins de tokens pour le même résultat.
- : Le micro est dans le composer, le texte atterrit dans le brouillon, pas de copier-coller.
- : Sur le téléphone, maintenez le micro et le texte apparaît dans votre agent desktop via le relay chiffré.
La dictée vocale est le moyen le moins cher de rendre chaque prompt plus long, plus précis et plus rapide à écrire, en même temps.
À quoi ressemble un prompt dicté
Vous n'avez rien à écrire de tout ça. Vous le dites à voix haute, la reconnaissance le transforme en le prompt ci-dessous, et vous appuyez sur Entrée. Essayez de taper un prompt aussi détaillé et mesurez le temps que ça prend.
Dicté au micro
Ajoute un rate limiter sur l'endpoint de login.
Utilise une fenêtre glissante de cinq tentatives par minute et par IP.
Renvoie un 429 avec un header Retry-After quand la limite est atteinte.
Ne touche pas au chemin de succès existant.
Ajoute un test unitaire pour la limite atteinte et un pour la remise à zéro après une minute.
Ne touche pas à l'endpoint d'inscription.FAQ
C'est quoi la dictée vocale dans AgentsRoom ?
La dictée vocale est un bouton micro dans le composer de l'agent qui transforme votre voix en texte. Vous cliquez le micro, vous dictez votre prompt, et le texte transcrit s'insère dans le brouillon à votre curseur. C'est de la reconnaissance vocale intégrée pour écrire des prompts à vos agents IA, sans app de dictée séparée et sans copier-coller entre fenêtres.
Pourquoi dicter mes prompts au lieu de les taper ?
Vitesse, précision et économie de tokens. Vous parlez plusieurs fois plus vite que vous ne tapez, les prompts prennent donc des secondes au lieu de minutes. Comme dicter ne coûte presque rien, vous en dites plus naturellement, ce qui rend le prompt plus précis. Un prompt précis, ce sont moins d'allers-retours de clarification avec l'agent, donc moins de tokens pour le même résultat.
Quels modèles de transcription puis-je utiliser ?
Sur le desktop, vous choisissez parmi trois modèles de reconnaissance dans les réglages : GPT-4o Transcribe (le défaut, meilleure qualité multilingue), GPT-4o mini Transcribe (presque aussi précis et moins cher), et Whisper d'OpenAI, le modèle whisper-1, tarifé simplement à la minute avec une base multilingue solide.
C'est juste Whisper d'OpenAI ?
Whisper est l'un des modèles que vous pouvez choisir, intégré directement dans le composer plutôt que lancé comme une app séparée à côté. Vous pouvez aussi prendre GPT-4o Transcribe ou GPT-4o mini Transcribe. L'intérêt de la dictée vocale d'AgentsRoom, c'est qu'elle vise directement l'input du prompt de votre agent, vous ne dictez donc pas dans une fenêtre pour copier-coller dans une autre.
Quelles langues la dictée vocale supporte-t-elle ?
Seize langues parlées plus la détection automatique : anglais, français, espagnol, allemand, italien, portugais, russe, chinois, japonais, coréen, arabe, hindi, indonésien, polonais, turc et vietnamien. L'auto-détection est le défaut. Vous pouvez forcer une langue précise dans les réglages quand les courts enregistrements sont mal détectés.
Ma voix part-elle vers un serveur ?
Ça dépend de la surface. Sur le desktop, l'audio est envoyé au backend de transcription d'AgentsRoom, qui exécute la reconnaissance sur le modèle choisi et renvoie le texte. Sur mobile, la reconnaissance tourne on-device, l'audio ne quitte donc pas votre téléphone et seul le texte reconnu est relayé vers le desktop via la connexion chiffrée de bout en bout.
Le prompt part-il automatiquement après la dictée ?
Non. La dictée vocale dépose toujours le texte dans le brouillon, jamais dans l'envoi. Vous relisez la transcription, vous corrigez le rare mot mal entendu, vous ajoutez ou réorganisez au clavier si vous voulez, et vous appuyez sur Entrée quand vous êtes prêt. Vous gardez le contrôle de ce que votre agent reçoit exactement.
Puis-je mélanger frappe et dictée dans le même prompt ?
Oui. Le texte s'insère à votre curseur, pas à la place de tout le brouillon. Vous pouvez taper la première moitié, dicter un long paragraphe au milieu, puis taper une dernière ligne. La dictée vocale est un moyen plus rapide de remplir le composer, totalement compatible avec le clavier.
Puis-je dicter depuis mon téléphone vers un agent sur mon Mac ?
Oui. L'app compagnon mobile a un bouton micro : maintenez-le, parlez, relâchez. La parole est reconnue on-device et le texte est relayé chiffré de bout en bout vers l'agent que vous avez focalisé sur le desktop. C'est le moyen le plus rapide d'envoyer un prompt à votre agent Mac sans clavier mobile.
La dictée vocale marche-t-elle avec Claude Code, Codex et Antigravity ?
Oui, avec tous, plus OpenCode et Aider. Le texte dicté n'est que du texte dans le composer, et la configuration de transcription est neutre vis-à-vis du provider, la dictée vocale se comporte donc à l'identique quel que soit le CLI d'agent que vous faites tourner.
Va bien avec
Scratchpad
Un éditeur de prompt plus grand dans le footer. Dictez un brief long, affinez-le dans le scratchpad, puis envoyez-le à votre agent.
Bibliothèque de prompts
Sauvegardez les prompts que vous dictez comme modèles réutilisables. La voix écrit le premier jet, la bibliothèque garde les bons.
Sync mobile-desktop
Le lien chiffré de bout en bout qui transporte votre texte dicté du téléphone vers l'agent focalisé sur votre Mac.
Contrôle des agents à distance
Pilotez vos agents desktop depuis votre téléphone. La dictée est le moyen le plus rapide de leur envoyer un prompt loin du clavier.
Multi-fournisseur
Faites tourner Claude, Codex, Antigravity, OpenCode et Aider côte à côte. La dictée vocale marche pareil sur chacun d'eux.
Sketch
Dessinez et annotez dans le composer. Associez un prompt dicté à un croquis rapide pour donner à votre agent les mots et l'image.
Parlez à vos agents, arrêtez de taper vos prompts
Téléchargez AgentsRoom et dictez vos prompts directement dans le composer. Plus rapides à écrire, plus riches en contexte, plus légers en tokens. La dictée vocale intégrée à votre IDE d'agents IA, sur desktop et sur mobile.
App companion : suivez vos agents en déplacement
Utilisez Claude, Codex, Antigravity CLI ou un autre fournisseur IA.
Remontez bugs et demandes directement dans votre backlog public.
Aperçu d'AgentsRoom en action.